
 In a previous post we covered time series data.
In a previous post we covered time series data.
We talked about how process automation and control data can feed our big data applications and cloud-based software platforms, to build Industrial Internet of Things applications.
In this post we'll take a look at how time series data can be used to develop time series models.
As the name suggests, time series modeling involves using time-based data (years, days, hours, minutes) to derive hidden insights that will help us predict future outcomes—like when a pump might fail, or when a bearing might wear out.
Time series models are very useful when you have serially correlated data. Kind of like the data we’re all used to collecting in our HMI software for things like historical trending.
A number of tools out there can help you build time series models. We’ll just cover the most widely used applications you may want to be aware of, as you journey through the IoT and predictive analytics frontiers.
 Now there’s a lot of pretty high-level math that goes into building these types of models. But that’s the beauty of the software applications below: they do the heavy lifting for you and already have all of the predictive analytics algorithms and models built in.
Now there’s a lot of pretty high-level math that goes into building these types of models. But that’s the beauty of the software applications below: they do the heavy lifting for you and already have all of the predictive analytics algorithms and models built in.
So in some cases you can literally paste a comma-delimited file or spreadsheet into the software package, and it will do the work for you from there.
SPSS Modeler From IBM
IBM SPSS Modeler is a predictive analytics platform that helps you build accurate predictive models quickly and then share that information with individuals, groups, and systems. It provides a range of advanced algorithms and analysis techniques, including text analytics, entity analytics, decision management, and optimization. It's designed to help make better decisions, either from an individual's desktop or within operational systems.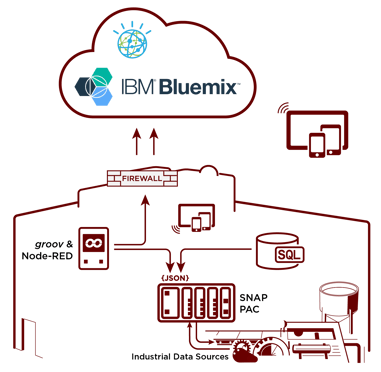
One of the benefits SPSS Modeler offers is a graphical user interface, so you can build predictive models without having to write any programming code. It uses a visual work palette with a drag-and-drop interface to apply various algorithms to the data sources you supply.
This is a huge help, because it means you don’t have to be a data mining expert or a programmer to get started building your predictive analytics applications.
SPSS Modeler also has linguistic technologies, like natural language processing, to automatically extract and organize key concepts from text. It will also make an attempt to structure your data into meaningful groups.
SPSS Modeler also has something called Entity Analytics built into it to help clean up your data if it’s not 100% accurate. It will look for things like duplicates, and identify relationships that might be hidden within the data itself.
For example, you might be able to identify which vendor's pump or motor fails more often, given a certain set of circumstances. Armed with that type of information, you can make better procurement decisions down the road. You can even start to build predictive models that indicate potential failures, given a set of current circumstances like weather, run time, etc.

SAS
SAS (Statistical Analysis Software) started off as a software language for data analysis but has since grown into a suite of tools for crunching big data.
It mines, alters, manages, and retrieves data from a variety of sources and performs statistical analysis on it. SAS offers a graphical point-and-click, drag-and-drop interface for those new to mining data, as well as a powerful programming language (called SAS) for more advanced data-scientist users.
SAS does require data to be formatted in a spreadsheet table or in their specific SAS format. This requirement may make it less flexible for ingesting and analyzing the massive amounts of unstructured data our legacy industrial automation assets generate today.
In the past, SAS has been credited with the widest breadth of statistical analysis tools. But it also may have the steepest learning curve, as the graphical user interface is not as mature and fully developed as in other platforms. However, it does provide enough functionality so that you don't have to write any code to build your application.
Python/Spark
Python is a programming language developed with a strong focus on business applications, not from an academic or statistical standpoint. This makes it very powerful when algorithms are directly used in applications.
Python's statistical capabilities are primarily focused on the predictive side. It's mostly used in data mining or machine learning applications, where a data analyst doesn’t need to intervene.
It's strong in analyzing images and videos, and is also the easiest language to use for big data frameworks like Apache Spark.
 Apache Spark is a fast, general-purpose cluster computing system for large-scale data processing. Apache offers a single framework for processing batch data and realtime data.
Apache Spark is a fast, general-purpose cluster computing system for large-scale data processing. Apache offers a single framework for processing batch data and realtime data.
Apache Spark is well suited for working with big data sets, but it also requires a lot of computer hardware resources to build out your cluster. It also supports high-level APIs in Java, Scala, and R in addition to Python.
It should also be noted that Apache Spark can be integrated with IBM’s SPSS Modeler for GUI-based access to Spark.
Wrapping Up
So now we've met some of the big data analysis platforms you might want to be familiar with, as you start your journey towards predictive analytics. But remember, the most important part of predictive analytics is first getting a data set to work with from our automation controllers and I/O.

And the easiest way to do that without having to write a single line of software code is Node-RED. You can learn more about Node-RED and its ability to wire together APIs, hardware devices, and online services in the video below.
You can also visit the Opto 22 developer site to see additional tools available to start building your IIoT application today.